
Trong kỷ nguyên công nghệ 4.0, Học máy (Machine Learning – ML) đã trở thành một trong những lĩnh vực quan trọng và có tác động mạnh mẽ nhất đến đời sống con người. Từ việc gợi ý sản phẩm trên các sàn thương mại điện tử, nhận diện khuôn mặt trên điện thoại thông minh, cho đến các hệ thống xe tự lái hay chẩn đoán bệnh trong y học, học máy đang âm thầm vận hành và mang lại những thay đổi lớn lao. Nhưng học máy hoạt động như thế nào, làm thế nào máy tính có thể “học” từ dữ liệu mà không cần lập trình cụ thể từng bước? Bài viết này sẽ giải thích nguyên lý, các thành phần chính và quy trình hoạt động của học máy một cách chi tiết và dễ hiểu.

1. Khái niệm cơ bản về học máy
Học máy là một nhánh của trí tuệ nhân tạo (Artificial Intelligence – AI), tập trung vào việc phát triển các thuật toán và mô hình giúp máy tính tự học từ dữ liệu. Thay vì viết ra từng dòng lệnh để xử lý một vấn đề cụ thể, các nhà phát triển cung cấp cho hệ thống dữ liệu đầu vào và một phương pháp học, từ đó máy tính tìm ra mối quan hệ, quy luật hoặc mô hình bên trong dữ liệu để đưa ra dự đoán hoặc quyết định cho dữ liệu mới.
Ví dụ: Khi muốn máy tính nhận diện hình ảnh con mèo, chúng ta không cần mô tả chi tiết “mèo có bốn chân, tai nhọn, râu dài…”. Thay vào đó, ta cung cấp hàng ngàn bức ảnh có hoặc không có mèo kèm nhãn (label), và thuật toán sẽ tự tìm ra những đặc trưng giúp phân biệt mèo với các đối tượng khác.
2.Thành phần chính trong học máy
Để hiểu cách học máy hoạt động, cần nắm rõ ba yếu tố cốt lõi:
- Dữ liệu (Data)
Dữ liệu là “nhiên liệu” của học máy. Chất lượng và số lượng dữ liệu quyết định độ chính xác của mô hình. Dữ liệu có thể là:
- Có cấu trúc: Dữ liệu dạng bảng, số liệu (ví dụ: thông tin khách hàng, giao dịch tài chính).
- Không có cấu trúc: Hình ảnh, âm thanh, văn bản, video,…
Dữ liệu thường được chia thành dữ liệu huấn luyện (training data) để máy học và dữ liệu kiểm tra (testing data) để đánh giá mô hình.
- Thuật toán (Algorithm)
Thuật toán là “bộ não” của hệ thống, quy định cách máy tính tìm ra quy luật từ dữ liệu. Có nhiều thuật toán khác nhau phục vụ từng mục đích, chẳng hạn:
- Hồi quy tuyến tính (Linear Regression): Dự đoán giá trị số (giá nhà, doanh thu…).
- Cây quyết định (Decision Tree): Phân loại dữ liệu theo các tiêu chí.
- Mạng nơ-ron nhân tạo (Artificial Neural Networks): Mô phỏng cách hoạt động của não người để xử lý dữ liệu phức tạp như hình ảnh hay ngôn ngữ.
- Mô hình (Model)
Mô hình là kết quả của quá trình huấn luyện thuật toán trên dữ liệu. Sau khi học xong, mô hình có khả năng dự đoán hoặc đưa ra quyết định khi gặp dữ liệu mới.

3. Các phương pháp học trong Machine Learning
Học máy được chia thành ba phương pháp chính dựa trên cách sử dụng dữ liệu:
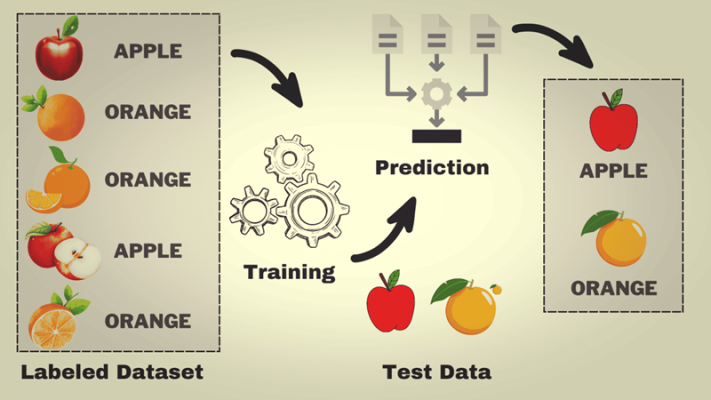
- Học có giám sát (Supervised Learning)
- Cách hoạt động: Máy được cung cấp dữ liệu đầu vào kèm đầu ra mong muốn (nhãn). Thuật toán học từ cặp dữ liệu này để dự đoán đầu ra cho dữ liệu mới.
- Ví dụ: Dự đoán giá nhà dựa trên diện tích và vị trí; phân loại email thành “spam” hoặc “không spam”.
- Thuật toán phổ biến: Hồi quy tuyến tính, hồi quy logistic, Support Vector Machine (SVM), Random Forest.
- Học không giám sát (Unsupervised Learning)
- Cách hoạt động: Dữ liệu không có nhãn, máy tự tìm ra cấu trúc hoặc mẫu ẩn trong dữ liệu.
- Ví dụ: Phân nhóm khách hàng theo hành vi mua sắm; phát hiện điểm bất thường trong giao dịch tài chính.
- Thuật toán phổ biến: K-Means Clustering, Hierarchical Clustering, PCA (Principal Component Analysis).
- Học tăng cường (Reinforcement Learning)
- Cách hoạt động: Máy học thông qua thử và sai, nhận “phần thưởng” hoặc “hình phạt” dựa trên hành động, từ đó tối ưu chiến lược.
- Ví dụ: Xe tự lái học cách tránh chướng ngại vật; robot học cách di chuyển trong môi trường mới.
- Ứng dụng: Game AI, điều khiển robot, quản lý năng lượng.
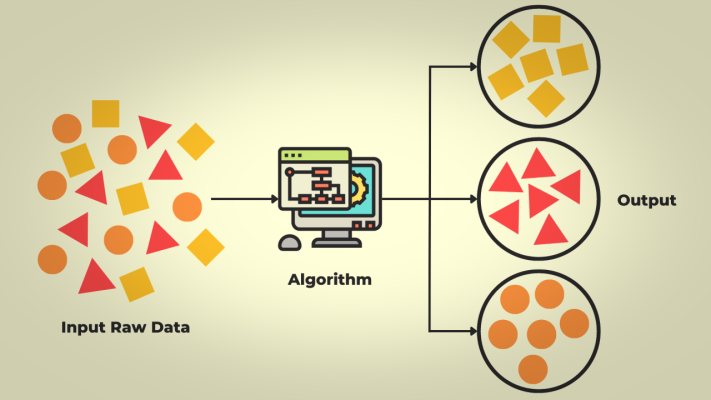
4. Quy trình hoạt động của học máy
Quá trình xây dựng và vận hành một mô hình học máy thường trải qua các bước sau:
Bước 1: Thu thập và chuẩn bị dữ liệu
- Thu thập dữ liệu từ nhiều nguồn: cảm biến, cơ sở dữ liệu, web, thiết bị IoT…
- Tiền xử lý dữ liệu: Làm sạch dữ liệu (loại bỏ giá trị thiếu, sai lệch), chuẩn hóa, chuyển đổi định dạng, loại bỏ nhiễu.
- Đây là giai đoạn tốn nhiều thời gian nhất (chiếm 60–80% công việc) vì dữ liệu thô thường không hoàn hảo.
Bước 2: Chia dữ liệu
Dữ liệu được chia thành:
- Tập huấn luyện (Training Set): Dùng để máy học quy luật.
- Tập kiểm tra (Testing Set): Đánh giá hiệu suất mô hình.
Ngoài ra còn có thể có tập xác thực (Validation Set) để điều chỉnh tham số.
Bước 3: Lựa chọn thuật toán và huấn luyện mô hình
Chọn thuật toán phù hợp với mục tiêu (dự đoán, phân loại, nhận diện mẫu). Máy tính sẽ lặp lại quá trình tính toán để giảm sai số giữa kết quả dự đoán và thực tế.
Bước 4: Đánh giá mô hình
Sử dụng dữ liệu kiểm tra để đo các chỉ số như:
- Độ chính xác (Accuracy)
- Độ nhạy (Recall)
- Độ đặc hiệu (Specificity)
- F1-Score
Việc đánh giá giúp xác định mô hình có đủ tốt để triển khai thực tế hay không.
Bước 5: Triển khai và cải tiến
Mô hình được tích hợp vào ứng dụng thực tế (ví dụ: hệ thống đề xuất sản phẩm). Khi dữ liệu mới xuất hiện, mô hình cần được cập nhật và tái huấn luyện để duy trì hiệu quả.
5. Thách thức trong học máy
Dù mang lại nhiều lợi ích, học máy cũng đối mặt với một số thách thức:
- Chất lượng dữ liệu: Dữ liệu không đầy đủ hoặc thiên lệch (bias) có thể dẫn đến kết quả sai lệch.
- Overfitting (Quá khớp): Mô hình học quá chi tiết từ dữ liệu huấn luyện, dẫn đến kém chính xác khi gặp dữ liệu mới.
- Chi phí tính toán: Một số mô hình phức tạp (như mạng nơ-ron sâu) đòi hỏi tài nguyên phần cứng lớn.
- Bảo mật và quyền riêng tư: Việc thu thập dữ liệu lớn tiềm ẩn nguy cơ vi phạm quyền riêng tư người dùng.
6. Ứng dụng thực tế của học máy
Học máy đã len lỏi vào hầu hết các lĩnh vực:
- Thương mại điện tử: Hệ thống gợi ý sản phẩm của Amazon, Shopee, Lazada.
- Y tế: Dự đoán bệnh tật, phân tích hình ảnh y học, hỗ trợ chẩn đoán ung thư.
- Tài chính: Phát hiện gian lận, dự báo thị trường chứng khoán.
- Giao thông: Xe tự lái, điều khiển tín hiệu đèn giao thông thông minh.
- Truyền thông – Giải trí: Gợi ý phim của Netflix, đề xuất nhạc của Spotify.
7. Tương lai của học máy
Với tốc độ phát triển nhanh chóng của dữ liệu lớn (Big Data) và sức mạnh tính toán, học máy sẽ tiếp tục mở rộng ảnh hưởng. Các hướng phát triển mới như học sâu (Deep Learning), xử lý ngôn ngữ tự nhiên (NLP), hay AI tổng hợp (Generative AI) hứa hẹn mang đến những bước tiến vượt bậc, giúp máy tính ngày càng thông minh và linh hoạt hơn.
Kết luận
Học máy hoạt động dựa trên nguyên lý máy tính học từ dữ liệu để tìm ra quy luật và đưa ra dự đoán, thay vì phải lập trình chi tiết từng thao tác. Quá trình này bao gồm nhiều giai đoạn từ thu thập, xử lý dữ liệu, lựa chọn thuật toán, huấn luyện, đánh giá đến triển khai thực tế. Dù còn tồn tại những thách thức, học máy vẫn đang và sẽ tiếp tục đóng vai trò chủ chốt trong việc định hình tương lai của công nghệ, giúp con người giải quyết những vấn đề phức tạp và tối ưu hóa mọi lĩnh vực của đời sống.